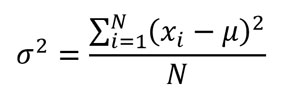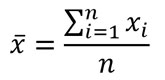La teoría de la probabilidad es
una herramienta matemática que establece un conjunto de reglas o principios
útiles para calcular la ocurrencia o no ocurrencia de fenómenos aleatorios y
procesos estocásticos.
En otras palabras, la teoría de la
probabilidad está compuesta por todos los conocimientos relativos al concepto
de probabilidad. Se trata de un concepto, en esencia, matemático. Así mismo, la
probabilidad como rama de las matemáticas constituye un instrumento para la
estadística.
Así, en el caso de una moneda,
sabemos que al tirarla sobre un tablero el resultado puede ser cara o cruz.
Suponiendo que la moneda y el tablero son perfectos y que las condiciones de
lanzamiento no cambian, la probabilidad debe ser de 50% cara y 50% cruz.
En este punto nace el concepto de
probabilidad. La probabilidad es un número entre 0 y 1, habitualmente expresado
en % entre 0 y 100 que nos dice en cuántas ocasiones, de media, ocurrirá un
suceso cada 100 veces.
Con esto en mente, llegamos a la
conclusión, de que la teoría de la probabilidad se encarga de estudiar qué
número entre 0 y 1 debemos asignar a un determinado suceso. Es decir, se
encarga, de estudiar las probabilidades de suceder de un evento.
Conceptos fundamental
En cualquier caso, sin desviarnos del concepto de teoría de la probabilidad, diremos que está formada por un conjunto de técnicas que nos permiten asignar un número a la posibilidad de que un evento ocurra.
La teoría de la probabilidad es
una herramienta matemática que establece un conjunto de reglas o principios
útiles para calcular la ocurrencia o no ocurrencia de fenómenos aleatorios y
procesos estocásticos.
En otras palabras, la teoría de la
probabilidad está compuesta por todos los conocimientos relativos al concepto
de probabilidad. Se trata de un concepto, en esencia, matemático. Así mismo, la
probabilidad como rama de las matemáticas constituye un instrumento para la
estadística.
Así, en el caso de una moneda,
sabemos que al tirarla sobre un tablero el resultado puede ser cara o cruz.
Suponiendo que la moneda y el tablero son perfectos y que las condiciones de
lanzamiento no cambian, la probabilidad debe ser de 50% cara y 50% cruz.
En este punto nace el concepto de
probabilidad. La probabilidad es un número entre 0 y 1, habitualmente expresado
en % entre 0 y 100 que nos dice en cuántas ocasiones, de media, ocurrirá un
suceso cada 100 veces.
Con esto en mente, llegamos a la
conclusión, de que la teoría de la probabilidad se encarga de estudiar qué
número entre 0 y 1 debemos asignar a un determinado suceso. Es decir, se
encarga, de estudiar las probabilidades de suceder de un evento.
Historia de la teoría de la
probabilidad
La probabilidad como concepto
existe desde hace miles de años. Hay evidencias históricas, que nos indican que
la primera civilización (Sumeria) era capaz de construir dados de 4 caras
trabajando con huesos. Más tarde, primero en Egipto y luego en Grecia y Roma,
los juegos de azar se hicieron populares.
Sin embargo, y a pesar de todo,
las primeras publicaciones que acuñaban o intuían el concepto de probabilidad
se escribieron a mediados del siglo XVI. Concretamente, fue Gerolamo Cardano
quien escribió en 1553 un tratado sobre el juego de dados. Aunque su obra no
sería publicada hasta 110 años más tarde, en 1663.
Posteriormente, han surgido
avances gracias a diversos intelectuales que han permitido con sus
publicaciones aumentar y mejorar el conocimiento de la probabilidad. Ejemplo de
ello son intelectuales como Laplace, Gauss o Kolmogorov.
Diferencia entre estadística y
probabilidad
Como decíamos al inicio
estadística y probabilidad son habitualmente confundidos. Son conceptos
relacionados pero bajo ningún concepto son sinónimos. La diferencia puede
parecer, en un principio, algo sin importancia. Nada más lejos de la realidad.
Conocer la diferencia entre uno y otro concepto nos ayudará a entenderlos mejor
y obtener un conocimiento más preciso de la materia.
Así pues, la teoría de la
probabilidad constituye un aparato matemático. Una herramienta que proviene de
la ciencia matemática. La estadística, por decirlo de alguna manera, se sirve
de dicha herramienta para poder llegar a conclusiones más precisas. Por tanto,
probabilidad no es lo mismo que estadística. Y de hecho, es más, ni siquiera es
una rama de la estadística.
Conviene destacar que probabilidad
y estadística no son la misma cosa. Son dos conceptos relacionados pero
diferentes. Al final de este artículo, explicaremos la diferencia entre estos
dos términos.
El concepto de probabilidad
En cualquier caso, sin desviarnos
del concepto de teoría de la probabilidad, diremos que está formada por un
conjunto de técnicas que nos permiten asignar un número a la posibilidad de que
un evento ocurra.
https://www.youtube.com/watch?v=Nda59uLvaQc&feature=emb_title
PARA REFORZAR ESTOS TEMAS REALIZAMOS UNA LÍNEA DEL TIEMPO DE LA HISTORIA DE LA PROBABILIDAD.
HABLANDO DE TODOS LOS TEMAS ANTES VISTOS COMO PROYECTO FINAL REALIZAMOS UN VIDEO EN REALIDAD AUMENTADA EXPLICANDO LAS MEDIDAS DE TENDENCIA CENTRAL Y HACIENDO UNA ENCUESTA CUALITATIVA A UNA MUESTRA DE UNA POBLACIÓN DE 32 PERSONAS, EN LA CUAL PUSIMOS LOS RESULTADOS EN SUS RESPECTIVAS GRÁFICAS.
PUEDEN VISUALIZARLO EN EL SIGUIENTE LINK: